


 ScanSnapの使い方 本をスキャンして電子書籍にする方法
ScanSnapの使い方 本をスキャンして電子書籍にする方法
書籍を解体/スキャンして電子書籍に変換する事を、俗称で「自炊」と呼びます。
ここでは、ディスクカッターとドキュメントスキャナ:ScanSnapを使った、自宅で手軽にできる電子書籍の作り方を解説します。
なお、「自炊」の方法全般については、自分で電子書籍を作る方法/自炊のしかたで紹介しています。
併せてご参照ください。
ディスクカッターで本を解体
ディスクカッターで本を解体してみましょう。 使用したモデルは定番のカール事務器 DC-F5100 です。
慣れてしまえば解体にかかる時間は3分、ディスクカッターでのカットに2分半、合計6分弱で終わる作業です。
カール事務器からは、ほかにもよりコンパクトな
DC-2000
なども発売されています。
です。
慣れてしまえば解体にかかる時間は3分、ディスクカッターでのカットに2分半、合計6分弱で終わる作業です。
カール事務器からは、ほかにもよりコンパクトな
DC-2000
なども発売されています。
ディスクカッターを探す(Amazon.co.jp)
 まず表紙と中表紙を外します。これらは別途「カラー」モードでスキャンします。
表紙はできるだけ平らになるよう、折り目は逆方向にまげて、折り癖を消しておきます。
本体から中表紙を破かないように外すのが、解体工程で一番難しく、力がいるところです。
まず表紙と中表紙を外します。これらは別途「カラー」モードでスキャンします。
表紙はできるだけ平らになるよう、折り目は逆方向にまげて、折り癖を消しておきます。
本体から中表紙を破かないように外すのが、解体工程で一番難しく、力がいるところです。
 本体を、30~40枚(60~80ページ)ごとの束に分解していきます。
コミックスなら3~4分割します。
カッティングマットの上で、本体を大きく開いて、カッターで丁寧に切り離します。
やや大きめの、グリップのしっかりしたカッターを使うのがコツです。
ここで使用したカッターは オルファ リミテッド NL LTD-07 です。
以上で解体完了です。
本体を、30~40枚(60~80ページ)ごとの束に分解していきます。
コミックスなら3~4分割します。
カッティングマットの上で、本体を大きく開いて、カッターで丁寧に切り離します。
やや大きめの、グリップのしっかりしたカッターを使うのがコツです。
ここで使用したカッターは オルファ リミテッド NL LTD-07 です。
以上で解体完了です。
カッティングマットを探す(Amazon.co.jp)
オルファ リミテッドを探す(Amazon.co.jp)
 ディスクカッターで本体の束を順にカットしていきます。
ケチらず大胆に、糊の部分が残らないよう、6~7mmくらいの幅でカットします。
本体を適切な枚数で分割していれば、ディスクカッターは一束5~6往復させればカットできます。
束ごとにカットしたらすぐスキャンしていくと、効率が良いかも。
ディスクカッターで本体の束を順にカットしていきます。
ケチらず大胆に、糊の部分が残らないよう、6~7mmくらいの幅でカットします。
本体を適切な枚数で分割していれば、ディスクカッターは一束5~6往復させればカットできます。
束ごとにカットしたらすぐスキャンしていくと、効率が良いかも。
ここでもカラーページとモノクロページは分けて、スキャナのモードを切り替えてスキャンします。
ディスクカッターを探す(Amazon.co.jp)
ScanSnapの設定
つづいてScanSnapを使って解体した書籍をスキャンします。 使用したモデルは ScanSnap iX500
です。
慣れてしまえばコミック1冊のスキャンにかかる時間は8分程度です。
ScanSnap オフィシャルサイト (PFU)
 ScanSnapのセットアップ方法は、ScanSnapオフィシャルサイトの
ScanSnapを始めましょう (PFU)
のページで読めます。
まずはパソコンに「ScanSnap Home」アプリをインストールして、ScanSnapとの接続を終えてください。
ScanSnapのセットアップ方法は、ScanSnapオフィシャルサイトの
ScanSnapを始めましょう (PFU)
のページで読めます。
まずはパソコンに「ScanSnap Home」アプリをインストールして、ScanSnapとの接続を終えてください。
ScanSnapの設定は「ScanSnap Home」アプリから呼び出します。 パソコンに接続したScanSnapの電源を入れた(給紙カバー(原稿台)を開けた)ときに表示される通知画面をクリックすると、「ScanSnap Home」アプリが起動します。
または、デスクトップにある
または、[スタート]-[すべてのアプリ]-[ScanSnap]-[ScanSnap Home]から起動します。
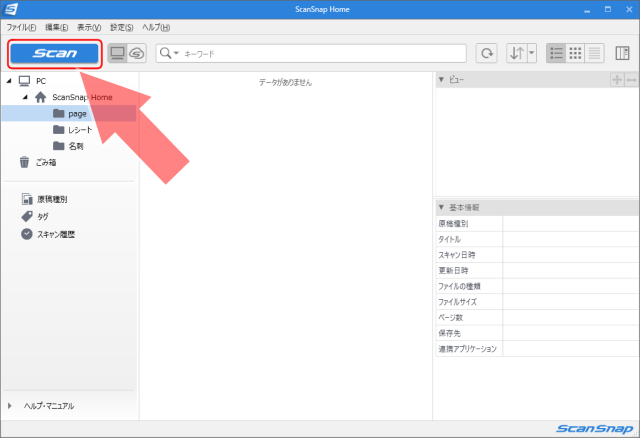
「ScanSnap Home」アプリが起動したら、画面左上の「Scan」ボタンをクリックします。
ScanSnapを始めましょう (PFU)
ScanSnap ドライバダウンロードページ (PFU)
 すると、スキャンに使用するプロファイル(設定)の選択画面になります。
まずは、自炊専用のプロファイルを新たに作っておきましょう。
画面右上の
すると、スキャンに使用するプロファイル(設定)の選択画面になります。
まずは、自炊専用のプロファイルを新たに作っておきましょう。
画面右上の
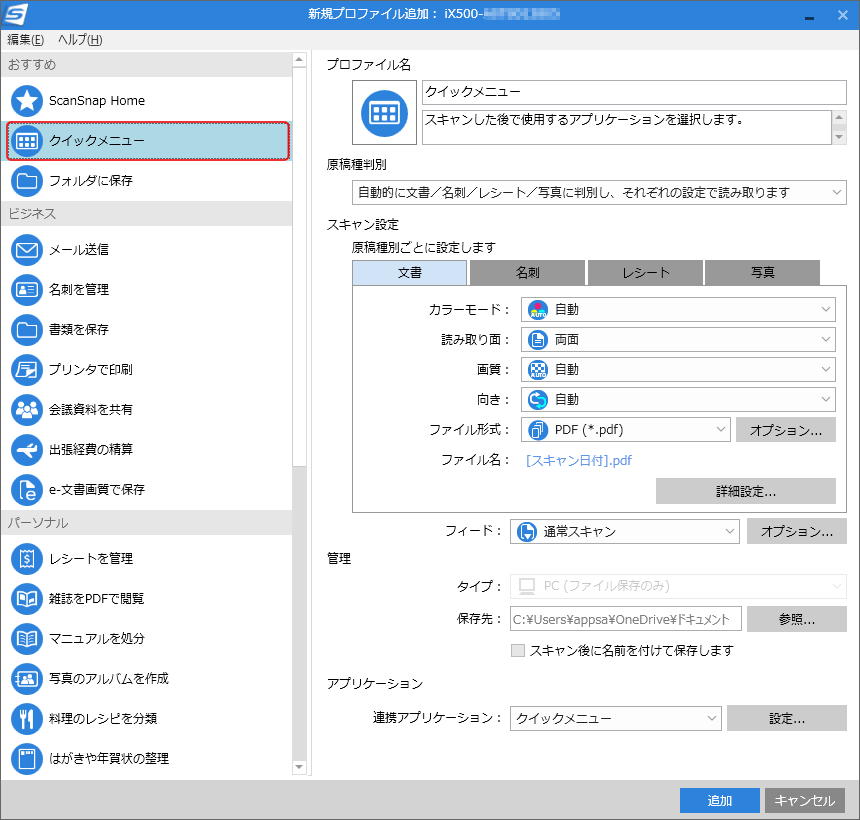
 あるいは既存のプロファイルを変更して使うのでも構いません。
変更したいプロファイル(例えば「クイックメニュー」)を選択して、画面右上の
あるいは既存のプロファイルを変更して使うのでも構いません。
変更したいプロファイル(例えば「クイックメニュー」)を選択して、画面右上の
つづいて画面の右の部分で、プロファイルの設定を行います。
そして最後に画面右下の「追加」ボタンをクリックすると、プロファイルが追加されます。
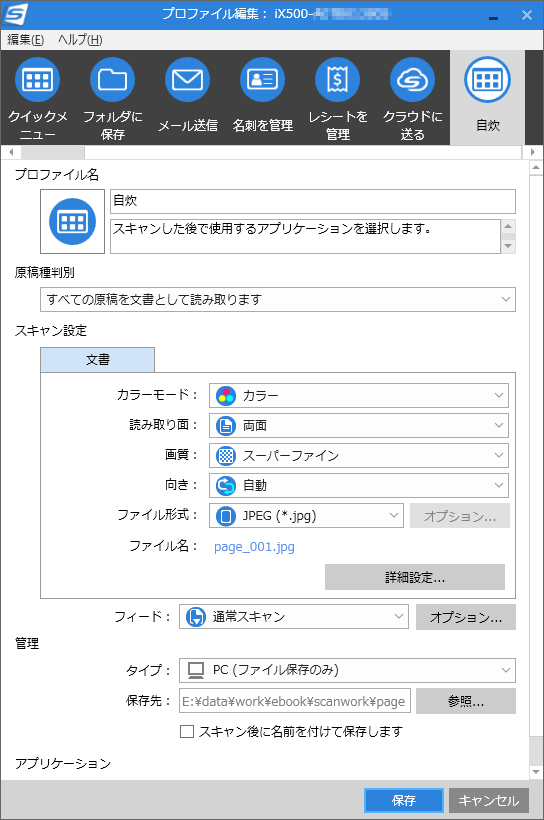 このように設定してみました。
このように設定してみました。
「プロファイル名」には「自炊」と入れました。 左にあるアイコンをクリックすると、アイコンのデザインを変更することができます。
「原稿種判別」は「すべての原稿を文書として読み取ります」を選択しました。 これを選ぶと、スキャン結果をJPEG画像またはPDFで保存できます。 また、その下の「スキャン設定」欄の表示が「文書」のみになります。
「スキャン設定」欄では、スキャン方法の細かい指定ができます。
「管理」欄では、スキャン結果の保存先が指定できます。
「アプリケーション」欄では、スキャン後に起動するアプリを指定します。好みで指定して下さい。 特に理由がない限り「起動しません(ファイル保存のみ)」で良いと思います。
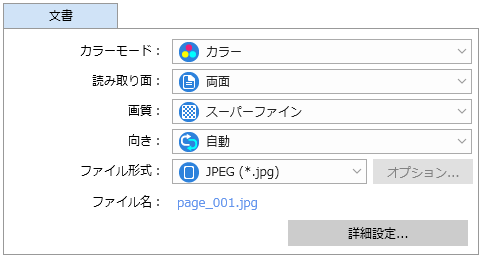 「スキャン設定」は図のように設定しました。
「スキャン設定」は図のように設定しました。
「カラーモード」の指定は原稿に合せます。 文庫本などのモノクロ原稿の場合は「グレー」がおすすめです。 カラーページがある場合は「カラー」がおすすめです。 モノクロページとカラーページについては、それぞれ設定を切り替えて、個別にスキャンするときれいに仕上がります。 なお、「カラー自動判別」を指定すると、モノクロページは「グレー」ではなく「白黒」で読み込まれるため、文字がとても読みにくくなります。 またモノクロページに「カラー」を指定すると、文字は読みやすくなりますが、ファイルサイズが不必要に大きくなってしまいます。
「読み取り面」は、原稿が両面印刷の場合は「両面」を指定します。
「画質」は「スーパーファイン」がおすすめです。
「向き」は、縦方向と横方向の原稿が混じっているときは「自動」にします。 しかし「自動」では、文字が少ないページでは判定を誤って、不要な回転が行われる場合があります。 自炊の場合は「回転しない」でもよいかもしれません。
「ファイル形式」では、PDFかJPEGが選択できます。 お好みで選んでください。
「詳細設定」ボタンをクリックすると、より詳細な設定が指定できます。
| 画質の選択 | スーパーファイン | |
|---|---|---|
| カラーモード | グレー | 文庫本の本文など、モノクロ原稿の読み込み時 |
| カラー | 表紙、カラーページの読み込み時 | |
| カラー自動判別 | 使用しない | 白黒 |
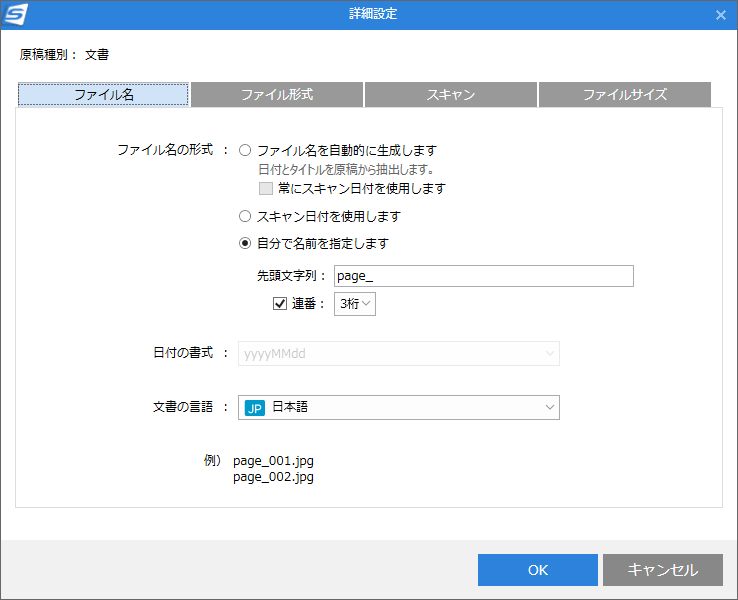 [詳細設定]-[ファイル名]画面では、スキャン結果ファイルにつける名前の、命名規則が指定できます。
画面の一番下には、指定した命名規則によって生成されるファイル名の例が表示されます。
[詳細設定]-[ファイル名]画面では、スキャン結果ファイルにつける名前の、命名規則が指定できます。
画面の一番下には、指定した命名規則によって生成されるファイル名の例が表示されます。
「文書の言語」では、読み取る文書に使用されている言語を指定します。 これはスキャンした文書を検索可能なPDFファイルにする場合に参照されます。
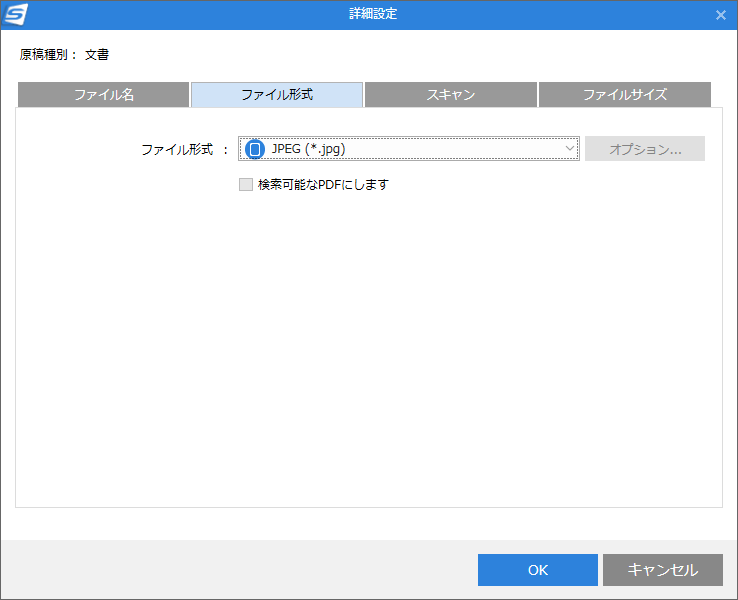 [詳細設定]-[ファイル形式]画面では、上でも解説したファイル形式が指定できます。
[詳細設定]-[ファイル形式]画面では、上でも解説したファイル形式が指定できます。
「検索可能なPDFにします」にチェックを入れると、 原稿をテキスト化して、スキャン結果のPDFファイルの中に埋め込む事ができ、検索可能なPDFファイルを作る事ができます。 最終的にテキストファイル/青空文庫形式/EPUB形式にしたい場合はこれを指定し、あとからテキストデータを抜き出します。
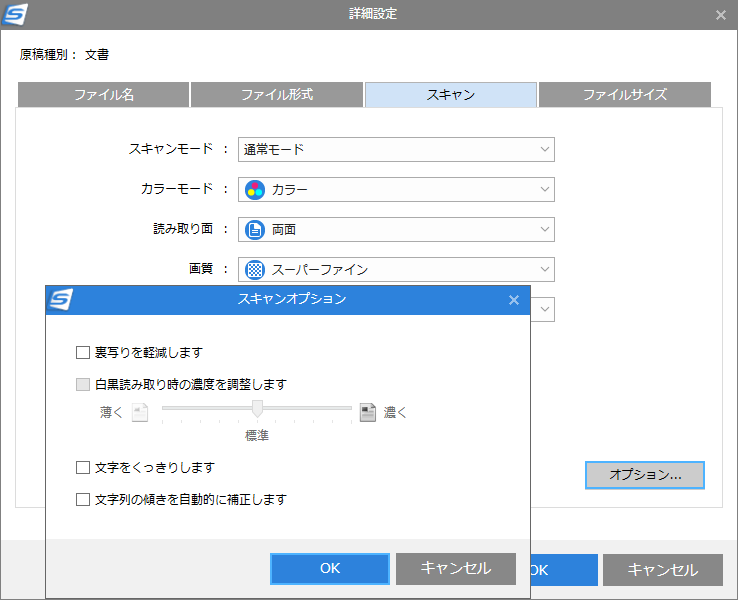 [詳細設定]-[スキャン]画面では、上でも解説したカラーモードや画質などが指定できます。
画面右下にある「オプション」ボタンをクリックすると、このような追加設定画面が現れます。
お好みで設定してください。
[詳細設定]-[スキャン]画面では、上でも解説したカラーモードや画質などが指定できます。
画面右下にある「オプション」ボタンをクリックすると、このような追加設定画面が現れます。
お好みで設定してください。
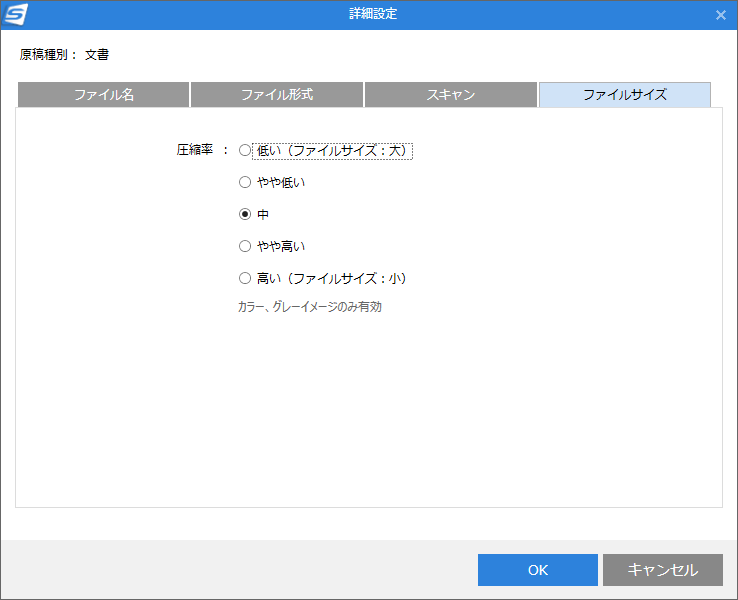 [詳細設定]-[ファイルサイズ]画面では、スキャン結果の画像の圧縮率が5段階で指定できます。
圧縮率を高くするとファイルサイズは小さくなりますが、文字や図が読みにくくなります。
初期値の「中」のままでOk。特に変更の必要はありません。
[詳細設定]-[ファイルサイズ]画面では、スキャン結果の画像の圧縮率が5段階で指定できます。
圧縮率を高くするとファイルサイズは小さくなりますが、文字や図が読みにくくなります。
初期値の「中」のままでOk。特に変更の必要はありません。
ScanSnapでスキャンを開始する
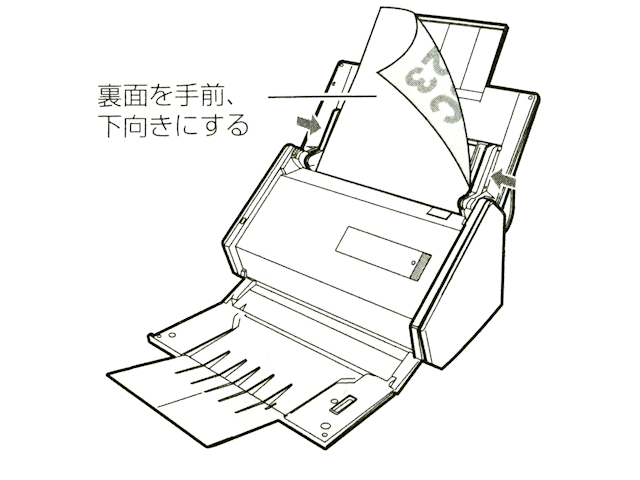 ScanSnap本体に原稿をセットします。
原稿は、図のように先頭ページを一番奥に、上下を逆にしてセットします。
正面から見たときに、一番最後のページがさかさまに見えているはずです。
ScanSnap本体に原稿をセットします。
原稿は、図のように先頭ページを一番奥に、上下を逆にしてセットします。
正面から見たときに、一番最後のページがさかさまに見えているはずです。
一度にセットする枚数は、紙の厚さにもよりますが、文庫・新書の場合は50枚/100ページ程度、フルカラーの書籍などの厚手の紙の場合は30枚/60ページ程度がよいと思います。
 ScanSnap本体にある、青く光っている「Scan」ボタンを押すとスキャンが始まります。
ScanSnap本体にある、青く光っている「Scan」ボタンを押すとスキャンが始まります。
あるいはアプリにある大きな「Scan」ボタンをクリックするとスキャンが始まります。
カラー表紙など長い原稿を読むときは、「Scan」ボタンを長押しして、点滅してから指を離すと読み取れます。 さもないと紙詰まりと判定され、途中で読み込みが停止します。
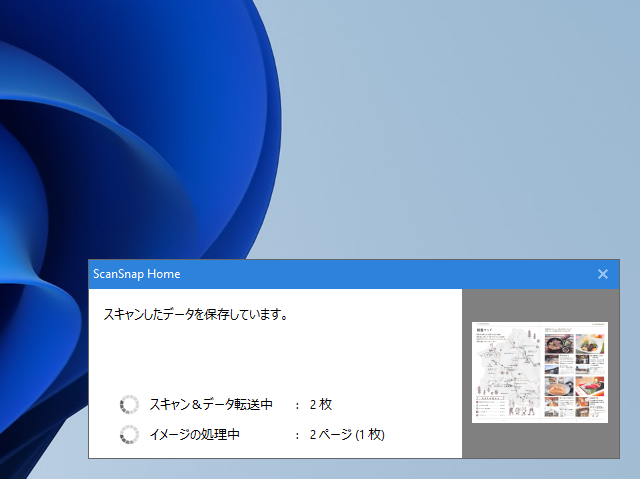 スキャン中は、画面右下に進捗状況が表示されます。
設定画面で指定したフォルダに、指定したファイル名でPDF/JPEGファイルが出力されているはずです。
なお、読み取りが終わるとこの画面は消えてしまいます。
スキャン中は、画面右下に進捗状況が表示されます。
設定画面で指定したフォルダに、指定したファイル名でPDF/JPEGファイルが出力されているはずです。
なお、読み取りが終わるとこの画面は消えてしまいます。
スキャン中にはほかのアプリで別のことをしていても構いません。
続きのページがあるときは、その原稿をセットして本体の青く光っている「Scan」ボタンを押せばOKです。 格納先フォルダの中身から、自動的に続きのファイル名を判別して格納してくれます。
 紙詰まりが頻繁に発生するようになったら、あるいはスキャンを終えたら最後にメンテナンスしましょう。
多くのページをスキャンすると、写真のグレーのリングに紙の粉がまとわりつき、紙を吸い込まなくなります。
これらのリングは容易に取り外せます。スキャン10冊に1回程度の割合で、取り外して洗いましょう。
紙詰まりが頻繁に発生するようになったら、あるいはスキャンを終えたら最後にメンテナンスしましょう。
多くのページをスキャンすると、写真のグレーのリングに紙の粉がまとわりつき、紙を吸い込まなくなります。
これらのリングは容易に取り外せます。スキャン10冊に1回程度の割合で、取り外して洗いましょう。
仕上げの調整
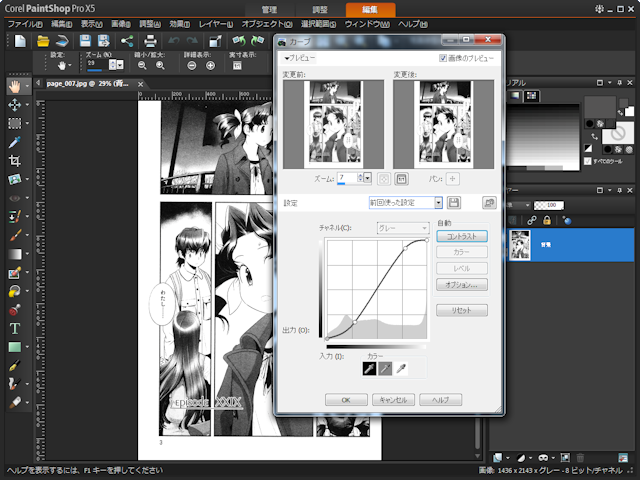 スキャンが終わったら仕上げの調整をしましょう。
モノクロページは、明るさとコントラストを調整します。
コーレル“Paintshop Pro”の場合なら[調整]-[明るさとコントラスト]-[カーブ]で図のようなカーブをかけるときれいに仕上がります。
これをスクリプトに登録して、全モノクロページに対して一括処理を行えばOKです。
スキャンが終わったら仕上げの調整をしましょう。
モノクロページは、明るさとコントラストを調整します。
コーレル“Paintshop Pro”の場合なら[調整]-[明るさとコントラスト]-[カーブ]で図のようなカーブをかけるときれいに仕上がります。
これをスクリプトに登録して、全モノクロページに対して一括処理を行えばOKです。
Paintshop Proを探す(Amazon.co.jp)
PDFファイルからテキストを取り出す
ScanSnap設定画面の「テキスト認識の選択」で「全ページ」を「検索可能なPDFにします」の指定を行っていれば、そのPDFファイルからテキストを抽出することが可能です。 ScanSnap本体に付属している、Adobe Acrobatを起動します。
ScanSnapで読み込んだPDFファイルを開きます。
ScanSnap本体に付属している、Adobe Acrobatを起動します。
ScanSnapで読み込んだPDFファイルを開きます。
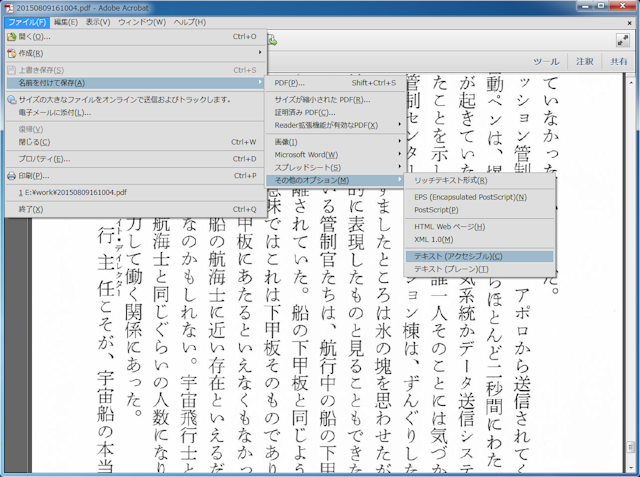 [ファイル]メニューから[名前を付けて保存]-[その他のオプション]-[テキスト(アクセシブルまたはプレーン)]を選びます。
するとテキストファイルの保存先を聞いてくるので、任意のフォルダ/ファイル名を指定します。
誤字の校正は必要ですが、全体の9割程度は正しいテキストに変換されます。
[ファイル]メニューから[名前を付けて保存]-[その他のオプション]-[テキスト(アクセシブルまたはプレーン)]を選びます。
するとテキストファイルの保存先を聞いてくるので、任意のフォルダ/ファイル名を指定します。
誤字の校正は必要ですが、全体の9割程度は正しいテキストに変換されます。
Free PDF to Text Converter(LotApps)
PDF からテキストを抜き出す!「PDF to Text Converter」(k本的に無料ソフト・フリーソフト)
